JSON Schema s'est imposé comme standard de description de structures JSON - APIs, pipelines ML, métadonnées. Une question peu étudiée reste ouverte : les générateurs open-source qui produisent automatiquement des instances valides à partir d'un schéma sont-ils fiables ? Ce stage au LIP6, équipe BD, avait pour objet de caractériser les limites de DataGen, l'un de ces générateurs, par rétro-ingénierie manuelle et analyse expérimentale sur corpus réels.
Le problème : génération optimiste et ses limites
Un générateur optimiste parie que la plupart des schémas sont simples - il génère une instance sans vérifier exhaustivement toutes les contraintes logiques, au risque de produire des instances invalides sur les schémas complexes. L'expressivité de JSON Schema rend ce pari risqué : les connecteurs logiques allOf, oneOf, anyOf, not peuvent se composer et s'imbriquer arbitrairement.
Exemple minimal d'un schéma qui piège un générateur optimiste - la propriété prop doit valoir exactement "mandatory", mais le générateur doit déduire cela de la conjonction d'un enum et d'une négation :
{
"type": "object",
"properties": {
"prop": {
"allOf": [
{ "enum": ["forbidden", "mandatory"] },
{ "not": { "enum": ["forbidden"] } }
]
}
},
"required": ["prop"]
}Rétro-ingénierie du pipeline DataGen
Le code source de DataGen est non documenté (commentaires en portugais) et dépourvu d'architecture explicite. La rétro-ingénierie a été conduite via le débogueur WebStorm, en instrumentant le back-end Docker avec des logs pour suivre l'évolution d'un schéma à chaque étape. Le pipeline interne se décompose en cinq étapes :
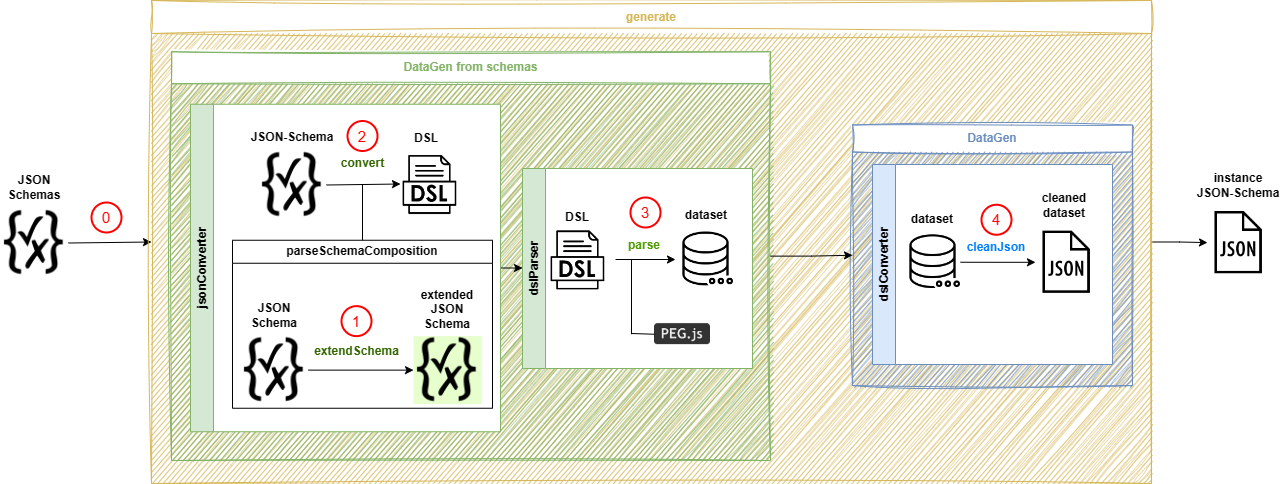
- Schéma d'entrée - un ou plusieurs schémas JSON, avec désignation du schéma racine pour permettre le référencement croisé.
- Schéma étendu -
schema_extenderanalyse les mots-clés de composition (allOf,anyOf,oneOf) et fusionne les sous-schémas dans le schéma de base.schema_inverterprend en charge la négationnoten produisant un schéma complémentaire - c'est ici que résident la plupart des défaillances observées. - DSL - représentation intermédiaire abstraite, indépendante de JSON/XML, plus facile à manipuler pour la génération.
- Dataset - instances synthétiques générées par randomisation à partir du DSL.
- Instance finale - sérialisation JSON ou XML via la bibliothèque interne, capable de gérer la récursivité et le regroupement.
Traitement par type
Chaque type primitif est traité par une fonction dédiée. Quelques comportements notables :
parseStringType- priorité au champpattern(génération via RandExp), puisformat(date-time, email, uuid…), sinon chaîne aléatoire entreminLengthetmaxLength. SiminLengthest absent, longueur entre 0 et 100.parseNumericType- extraitmultipleOf,minimum,maximum, contraintes exclusives. En absence de contraintes, génère aléatoirement entre −1 000 et 1 000. Valeur par défaut demultipleOf: 1 pour les entiers, 0,43 pour les flottants.parseObjectType- génère d'abord les propriétésrequired, puis les propriétés dépendantes (dependentRequired), lespatternProperties(RandExp), et enfin les propriétés additionnelles. Un objet vide est représenté par le sentinelDFJS_EMPTY_OBJECT.parseArrayType- génère lesprefixItems, puis les élémentscontainsdans les bornesminContains/maxContains, enfin remplit jusqu'àarrLen. SiuniqueItemsest actif, jusqu'à 10 tentatives pour garantir l'unicité.
Connecteurs logiques
Tous les connecteurs passent par parseAllSchemaComposition puis parseSchemaComposition :
- allOf - tous les sous-schémas sont fusionnés via
extendSchema. - oneOf / anyOf - un sous-schéma est choisi aléatoirement, les autres sont ignorés. C'est une approximation :
oneOfexige l'exclusivité, qui n'est pas vérifiée. - not - déclenche
schema_inverterqui applique des règles d'inversion par type :notNumericinverse les bornes,notStringinverse pattern/format/longueurs,notPropertiestransforme les propriétés autorisées en propriétés exclues. La compositionnotimbriquée dans un autre connecteur est la principale source d'instances invalides.
Protocole expérimental
Face à un code source sans documentation et des commentaires en portugais, nous avons adopté un protocole en quatre étapes :
- Migration de draft - les datasets couvrent les drafts v4, v6, v7 et 2019-09 ; DataGen n'implémente que la syntaxe 2020-12. Tous les schémas ont été traduits manuellement vers 2020-12.
- Génération de masse - exécution de DataGen sur l'ensemble des schémas, collecte simultanée des erreurs de génération.
- Validation - chaque instance générée est soumise à
json-schema-validator(Java/Jackson), 32× plus rapide que Fge, 5× plus rapide qu'Everit, support complet des drafts v4 à 2020-12. - Classification - les erreurs de validation sont regroupées par classe pour cibler l'analyse du code source.
Une étape annexe a consisté à instrumenter le back-end Docker avec des logs pour suivre l'évolution d'un schéma dans le pipeline - indispensable pour confirmer ou infirmer les hypothèses formulées sur le code.
Contraintes rencontrées
L'environnement Docker de DataGen (5 images, limite de requête à 102 400 octets) a imposé deux contournements : ignorer les schémas dépassant la limite, et fragmenter les datasets en lots avant la génération. Les erreurs 502 disparaissaient en répartissant la charge sur plusieurs requêtes plus petites. Le débogage sous WebStorm a aussi produit des instances vides récurrentes, probablement dues à un conflit de version JavaScript entre le runtime de DataGen et le débogueur.
Résultats sur 6 datasets réels
6 099 instances générées sur 6 datasets couvrant des domaines applicatifs distincts : Snowplow (analytics), WashingtonPost (presse), Kubernetes (infra), GitHub (API), Containment (schémas de test de containment), Handwritten (schémas manuels).
| Dataset | Schémas sat | Générés (sat) | Taux génération | Instances valides | Taux validité |
|---|---|---|---|---|---|
| Snowplow | 420 | 385 | 91,67 % | 351 / 385 | 91,16 % |
| WashingtonPost | 125 | 93 | 74,40 % | 91 / 93 | 97,85 % |
| Kubernetes | 1 087 | 862 | 79,30 % | 724 / 862 | 84,00 % |
| GitHub | 6 387 | 4 450 | 69,29 % | 3 765 / 4 450 | 84,61 % |
| Containment | 450 | 31 | 13,90 % | 3 / 31 | 9,68 % |
| Handwritten | 188 | 95 | 51,77 % | 15 / 95 | 15,79 % |
L'écart entre WashingtonPost (97,85 %) et Containment (9,68 %) n'est pas aléatoire : les datasets WashingtonPost et Snowplow contiennent principalement des schémas simples (objects plats, types primitifs). Containment et Handwritten sont construits pour tester les compositions logiques imbriquées - exactement le point faible identifié lors de la rétro-ingénierie.
5 classes d'erreurs identifiées
L'analyse croisée des erreurs de validation et du code source a permis d'isoler cinq classes d'erreurs distinctes, chacune documentée avec un schéma minimal reproductible :
- not imbriqué dans allOf/oneOf/anyOf - l'inversion de schéma est appliquée mais le résultat n'est pas reconcilié avec les contraintes du connecteur parent.
- oneOf sans vérification d'exclusivité - un sous-schéma est choisi aléatoirement ; si plusieurs sous-schémas sont satisfaisables par la même instance, la contrainte d'exclusivité de
oneOfest violée. - Inversion numérique incomplète -
notNumericinverse les bornes mais ne gère pas les cas où l'intervalle interdit est un sous-intervalle d'un intervalle plus large. - Compositions imbriquées multi-niveaux - la récursivité dans
parseAllSchemaCompositiontraite chaque niveau indépendamment sans propager les contraintes des niveaux parents. - Migration de draft incomplète - certains mots-clés renommés entre drafts (ex.
items→prefixItemsen 2020-12) produisent un schéma étendu incorrect si la traduction est partielle.
Conclusion
DataGen est performant sur les schémas industriels courants (80–98 % de validité sur Snowplow, WashingtonPost, Kubernetes). Son talon d'Achille est la composition logique imbriquée : dès qu'un not apparaît à l'intérieur d'un autre connecteur, ou que plusieurs connecteurs s'enchaînent sur plus d'un niveau, le taux de validité s'effondre.
Ce résultat confirme l'hypothèse des générateurs optimistes : ils fonctionnent bien tant que les schémas restent dans leur zone de confort. L'approche LLM, explorée en parallèle dans l'équipe, montre des résultats supérieurs (95–98 %) précisément sur ces cas de composition complexe - au prix d'une latence et d'un coût de génération incomparables.





