L'électrification automobile impose une validation exhaustive des systèmes batterie par essais destructifs. L'équipe Sécurité Batterie AMV-CPB4 d'Ampere génère plus de 130 000 fichiers d'essais par an - rapports PDF, fichiers Excel, enregistrements CAN, images thermiques, vidéos - traités manuellement, créant un goulot d'étranglement incompatible avec les objectifs d'industrialisation. L'objet du stage : concevoir et déployer un pipeline ETL cloud-native de bout en bout pour automatiser cette chaîne.
Audit de l'existant - projet SEADI
Le projet SEADI disposait d'un premier prototype : un script Python monolithique de 1 800 lignes structuré autour d'une fonction parcourir_dossiers() avec sept niveaux de boucles imbriquées, soit une complexité temporelle en O(n⁶). Le refactoring part de cet audit critique.
- 6 fonctions quasi-identiques (BRT, ESC, NI, NP, OVF, TS) totalisant 2 400+ lignes - duplication massive de la logique d'extraction.
- Consommation mémoire en
O(n × p × s): pour 50 fichiers PDF de 25 pages, 7,5 GB de RAM théorique. - 25+ transformations regex appliquées séquentiellement sur l'ensemble du dataset sans optimisation.
- Architecture non parallélisable - traitement séquentiel uniquement, testabilité réduite.
Architecture ETL cloud-native
L'architecture a été conçue de manière autonome et validée par l'Architecte Data IA, l'Expert Transformation Numérique et le Comité Technique CTT de Renault.
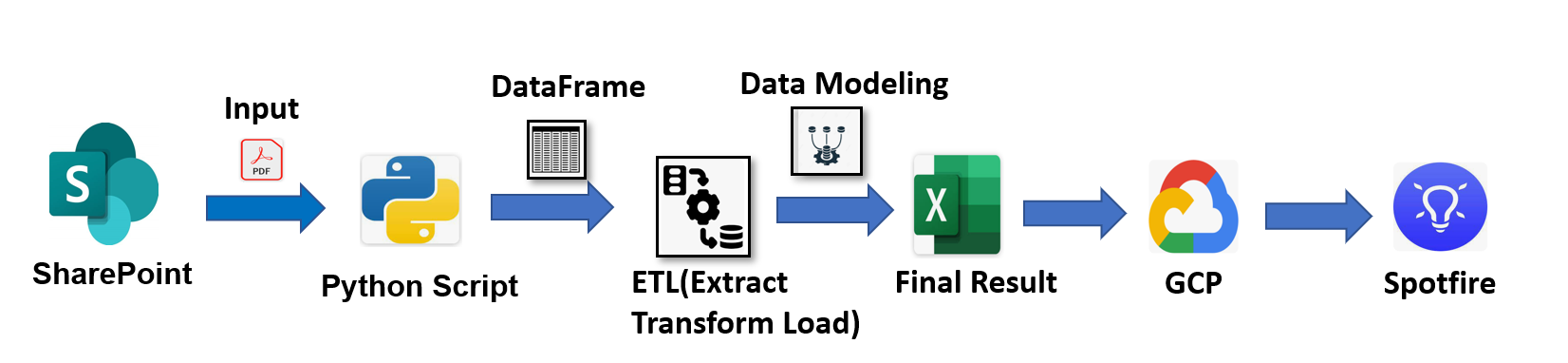
Le pipeline est décomposé en trois couches distinctes, remplaçant le script monolithique :
- Couche Extract - modules spécialisés par format (
pdf_extractor.py,file_reader.py) avec parseurs dédiés par type d'essai (brt_extractor.py,esc_extractor.py…). - Couche Transform - transformateurs spécialisés par domaine (
NumericalTransformer,ElectricalTransformer,VolumeTransformer) remplaçant les 25+ regex anarchiques. - Couche Load - persistance structurée (
file_writer.py,persistence.py) avec organisation raw / processed / final.
@dataclass
class ThermalStabilityTestData(BaseTestData):
t_fire: Optional[float] = None
volume_maximum: Optional[float] = None
def calculate_temperature_coherence(self) -> bool:
return self.t_fire >= self.t_leakage if both_existL'architecture dataclass avec validation automatique garantit la cohérence des données critiques et remplace les structures dict non typées du prototype initial.
Infrastructure GCP
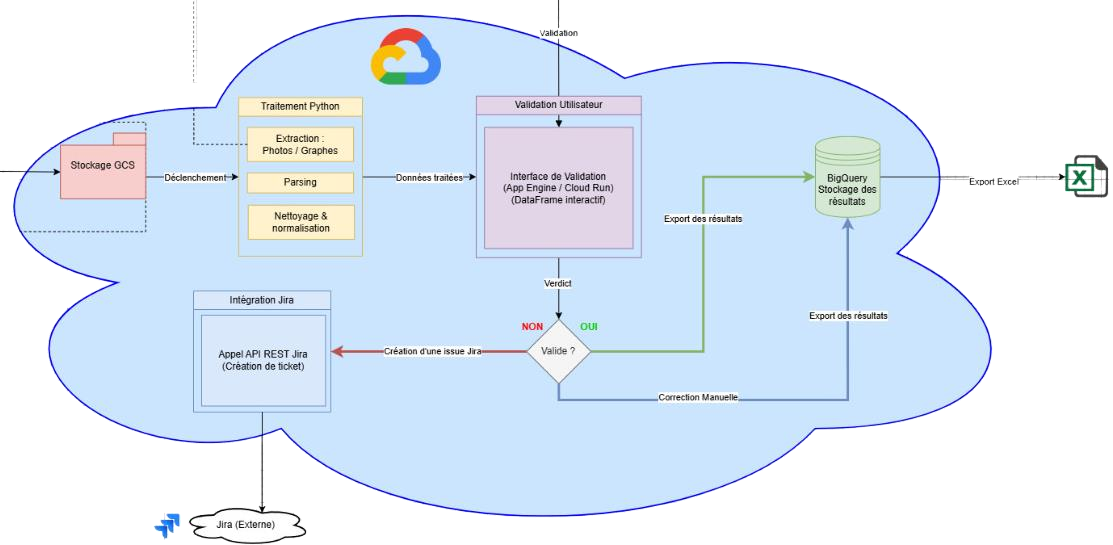
- Google Cloud Storage - organisation hiérarchique par type d'essai (cellule / module / pack) pour optimisation des traitements batch.
- Cloud Run serverless - scaling 0-to-N automatique, cold start <3 s, 1 vCPU / 2 Gi RAM.
- BigQuery - export structuré conforme au schéma RAWMUB (25 champs normalisés), typage rigoureux String / Integer / Float.
- GitLab CI/CD + Kaniko - build multi-stage sans daemon Docker, réduction image de 2,1 GB à 180 MB, registry mirror Renault réduisant les temps de build de 40 %.
Contrainte critique : les politiques de sécurité Renault bloquent l'API Microsoft Graph SharePoint. L'architecture adopte une approche hybride - récupération manuelle via drag & drop, traitement entièrement automatisé en aval.
Système de mapping et classification automatique
Face à des nomenclatures variables entre laboratoires (SERMA et fournisseurs externes), un système de classification automatique détecte le type d'essai depuis les chemins SharePoint d'origine :
type_patterns = {
'CELLULE': [r'\bcell\b', r'\bcellule\b', r'cell[_\s]'],
'MODULE': [r'\bmodule\b', r'\bmod\b', r'module[_\s]'],
'PACK': [r'\bpack\b', r'\bpk\b', r'pack[_\s]']
}
test_type_patterns = [
("NP", [r'\bnp\b', r'nail[\s_-]?penetration']),
("ESC", [r'\besc\b', r'external[\s_-]?short[\s_-]?circuit']),
("TS", [r'\bts\b', r'thermal[\s_-]?stability'])
]L'algorithme applique une stratégie en cascade (nom fichier → chemin SharePoint → contenu PDF) et génère un rapport pour les fichiers non classifiés, permettant l'amélioration continue des patterns.
Interface web de validation
Application full-stack Angular 18 / FastAPI déployée sur Cloud Run pour la validation métier des données extraites :
- 5 statuts de validation : Validé, Problématique, Draft, Corrigé, En attente - granularité adaptée aux workflows Safety.
- 212 tests traités avec édition en place, commentaires de validation et persistance JSON automatique toutes les 30 secondes.
- Export CSV conforme au schéma BigQuery RAWMUB pour chargement production via File Uploader Renault.
- Authentification PIV/CAC et composants Desyre (design system Renault) pour cohérence avec l'écosystème corporate.
Prototype computer vision YOLOv9
En collaboration avec une stagiaire spécialisée computer vision, développement d'un POC d'analyse automatique des vidéos d'essais destructifs :
- Pipeline d'entraînement complet avec augmentation de données (10 transformations : brightness, rotation, noise, CLAHE).
- Infrastructure d'annotation CVAT.ai avec export format YOLO.
- Validation sur 10+ vidéos d'essais - faisabilité technique confirmée.
- Limites identifiées : variabilité éclairage, angles caméra hétérogènes, dataset d'entraînement insuffisant pour industrialisation.
Le code (4 modules Python + configuration YAML) est documenté et transmis pour industrialisation future.
Benchmark IA générative vs parsing regex
Un test comparatif objectif sur un corpus représentatif de rapports PDF SERMA révèle un plafond de verre de l'approche par expressions régulières :
| Méthode | Taux de réussite | Robustesse | Maintenance |
|---|---|---|---|
| Parsing regex développé | 72–85 % | Fragile aux variations de template | Patterns à maintenir manuellement |
| Extraction LLM (ChatGPT interne) | 95–98 % | Adaptive - ajustement automatique | Auto-ajustement sans recalibrage |
Chaque amélioration d'un pattern pour un format de rapport génère des régressions sur d'autres, créant un équilibre autour de 85 %. Cette analyse justifie l'orientation vers une solution hybride (LLM pour extraction complexe + règles métier pour contrôle qualité) pour les évolutions futures du pipeline.
Dashboards Spotfire & documentation
Conception de 3 dashboards Spotfire 14.0.5 couvrant 12 KPIs Safety (volumétriques, qualité, temporels, opérationnels) pour les 20+ ingénieurs de l'équipe. Déploiement bloqué par des contraintes de licence Spotfire corporate - solution fonctionnelle en attente de résolution.
Livraison d'un manuel de passation de 33 pages couvrant procédures opérationnelles, architecture technique, scripts de dépannage et transfert des accès. Présentation de l'ensemble du projet devant le Comité Technique CTT avec validation positive des choix architecturaux.





