Génération de diagrammes de décision binaires réduits et ordonnés (ROBDD) avec une approche analogue à celle de Newton et Verna - A Theoretical and Numerical Analysis of the Worst-Case Size of Reduced Ordered Binary Decision Diagrams - suivie d'une comparaison expérimentale de nos résultats avec leurs données.
Représentation et construction
Chaque entier est d'abord décomposé en table de vérité via BigInteger (arithmétique arbitraire - contournement des limites des primitifs Java). La table alimente la construction récursive d'un arbre de décision binaire, chaque nœud portant son mot de Lukasiewicz calculé en post-ordre :
public static void lukaOnNode(Node root) {
if (root.left != null) {
lukaOnNode(root.left);
lukaOnNode(root.right);
root.setContent(
root.getContent()
+ "(" + root.left.getContent() + ")"
+ "(" + root.right.getContent() + ")"
);
}
}La longueur maximale d'un mot de Lukasiewicz à la racine d'un arbre de hauteur h est majorée par 11·2ʰ − 6 caractères (parenthèses + variables + feuilles au pire cas).
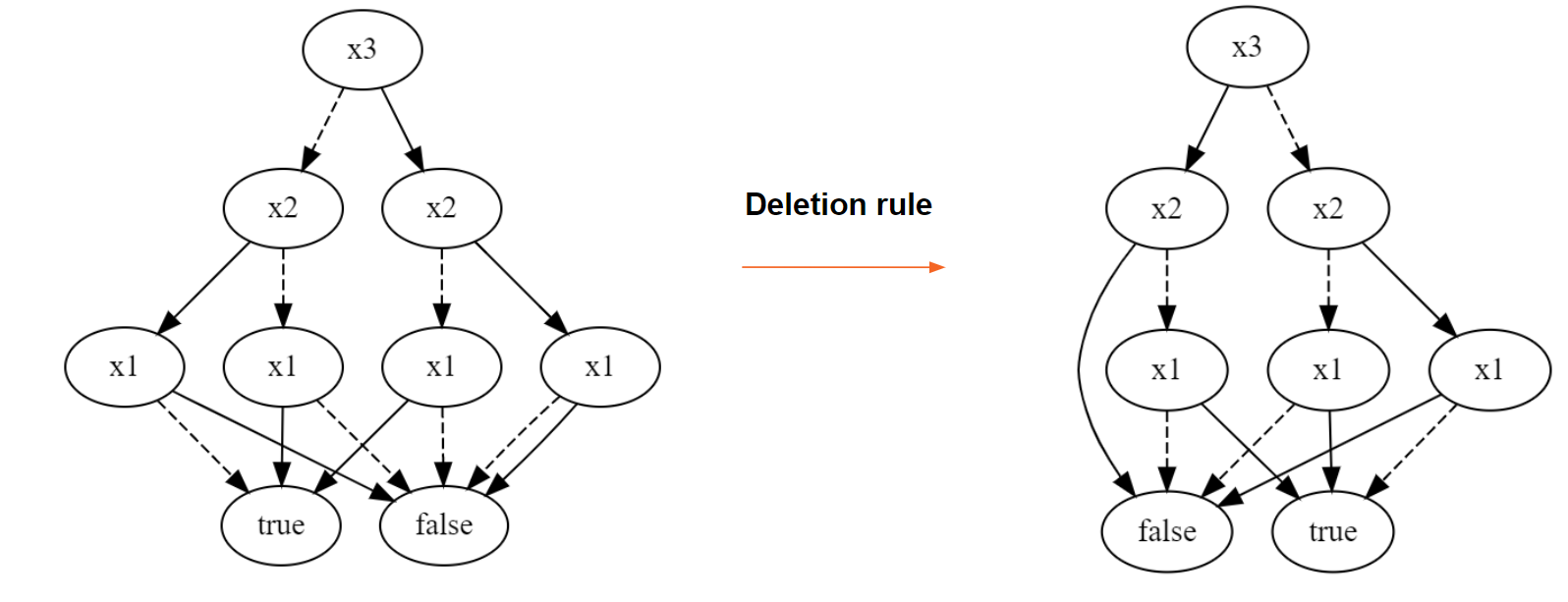
Les trois règles de réduction vers le ROBDD
La compression en ROBDD s'applique en trois passes successives :
- Terminal - fusion de toutes les feuilles de même valeur (
true/false) en un unique nœud terminal partagé. - Deletion - suppression des nœuds internes redondants dont les deux fils pointent vers le même nœud.
- Merging - partage des sous-arbres isomorphes : deux nœuds ayant le même mot de Lukasiewicz sont fusionnés.
La compression par Merging utilise une liste de pointeurs vers les mots uniques, puis ré-explore l'arbre pour remplacer les doublons :
public static Node getPointersFromPointersList(List<Node> theList, String content) {
for (int i = 0; i < theList.size(); i++)
if (theList.get(i).getContent().equals(content)) return theList.get(i);
return null;
}Analyse de complexité
Un arbre de hauteur h contient 2ʰ⁺¹ − 1 nœuds (2ʰ − 1 internes + 2ʰ feuilles). L'algorithme naïf de compression compare à chaque étage h les 2ʰ nœuds deux à deux, chaque comparaison portant sur un mot de longueur 11·2ʰ − 6 :
∑(h=0 to H) 2^h · (11·2^h - 6) ≈ 11H · 2^(2H) → O(2^(2h))Ramené au nombre de nœuds n (avec h ≈ log₂(n/2)), la complexité est en O(n log n).
Étude expérimentale - distributions de taille
On reproduit les histogrammes de Newton & Verna en générant tous les ROBDD pour 1 ≤ n ≤ 4 variables (2²ⁿ fonctions booléennes). Pour n ≥ 5, l'énumération complète devient impraticable :
| n | Fonctions booléennes (2²ⁿ) | Méthode | Temps estimé |
|---|---|---|---|
| 1–4 | 2 → 65 536 | Énumération complète | < quelques secondes |
| 5 | 4 294 967 296 | Échantillonnage aléatoire | ~2 j 11 h (énumération) |
| 6 | 1,84 × 10¹⁹ | Échantillonnage aléatoire | ~91 millions d'années |
| 7 | 3,40 × 10³⁸ | Échantillonnage aléatoire | > âge³ de l'univers |
| 10 | - | Échantillonnage aléatoire | - |
Pour n ≥ 5, on tire uniformément un échantillon de ROBDD et on observe que la distribution des tailles converge vers la courbe théorique de Newton & Verna, confirmant expérimentalement leurs résultats.