Étude expérimentale de la kernelization pour le problème du k-Vertex Cover. L'objectif : mesurer l'impact du prétraitement par crown decomposition sur un algorithme de branchement exact (VCB), en comparant les temps d'exécution avant et après réduction, sur des graphes aléatoires de densités variées.
Contexte théorique
Le k-Vertex Cover consiste à déterminer s'il existe un ensemble de sommets X ⊆ V, |X| ≤ k, tel que chaque arête du graphe est couverte par au moins un sommet de X. C'est un problème NP-complet dans sa forme générale, mais FPT (Fixed-Parameter Tractable) en k : il existe un algorithme en O(2ᵏ(n + m)).
La crown decomposition partitionne V en trois ensembles (C, H, R) : C est indépendant (couronne), H sépare C de R, et il existe un matching de taille |H| dans le sous-graphe induit par C ∪ H. Conséquence : H doit obligatoirement appartenir au vertex cover optimal, C peut être retiré, et k est décrémenté de |H|. Cette réduction itérée produit un noyau de taille au plus 3k.
Architecture du code
Six modules Python distincts, testés unitairement (suite complète passante) :
- crown_decomp.py - matching maximal glouton, construction du sous-graphe biparti, détection de la couronne via matching biparti (Hopcroft-Karp par composante connexe).
- kernel.py - application itérée des règles de réduction (sommets isolés, règle des hauts degrés, crown decomposition) jusqu'à point fixe ou taille ≤ 3k.
- reduction_rules.py - règle des hauts degrés : tout sommet de degré > k appartient obligatoirement au cover ; il est supprimé et k est décrémenté.
- vcb.py - branchement récursif : choisir une arête (u, v), explorer «u dans le cover» ou «v dans le cover», complexité O(2ᵏ(n + m)).
- generators.py - graphes aléatoires G(n, p) ou avec vertex cover garanti (chaque sommet hors cover lié à au moins un sommet du cover).
- benchmark.py - orchestration des expériences, calcul du speedup et des taux de réduction, production des figures (courbes, violons).
Plan d'expériences
Variables testées : taille n ∈ {30, 50, 70}, densité p ∈ {0.1, 0.3, 0.5}, paramètre k choisi comme fraction de n. Deux modes de génération : aléatoire pur et guaranteed_vc. 5 à 10 réplicats par configuration.
Métriques collectées pour chaque instance : temps VCB seul, temps de kernelization, temps VCB sur le kernel, speedup = t(VCB) / (t(kernel) + t(VCB_ker)), et taux de réduction ρ = 1 − |V_kernel| / |V_original|.
Résultats expérimentaux
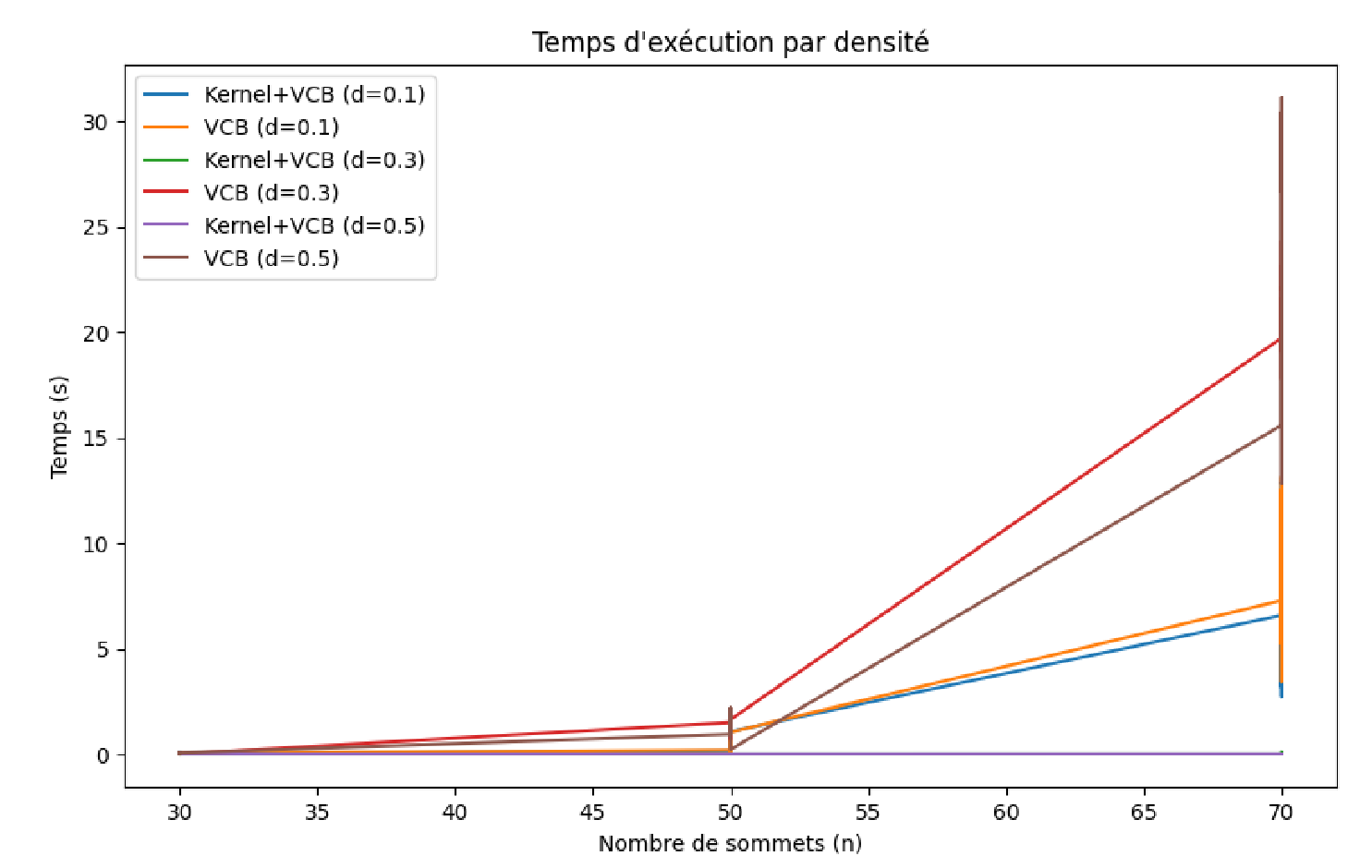
Trois enseignements principaux :
- Graphes peu denses (p = 0.1) - l'avantage du prétraitement est modeste : les courbes VCB seul et Kernel+VCB se rapprochent, la couronne est difficile à isoler dans un graphe épars.
- Graphes denses (p = 0.3 ou 0.5) - Kernel+VCB devient nettement plus performant. Pour p = 0.5, la courbe VCB seul explose bien plus rapidement.
- Taux de réduction - pour de faibles ratios k/n (≈ 0.22), la réduction atteint 40–50 % des sommets sur les instances aléatoires. Sur les instances guaranteed_vc, le ratio est plus faible car la structure imposée limite la détection de couronnes larges.
Distribution du speedup
Le diagramme violon révèle une grande disparité : pour p = 0.1 le speedup reste proche de 1 ; pour p = 0.3 et p = 0.5 des valeurs extrêmes dépassent parfois 1 000, voire 5 000 sur les instances aléatoires où la couronne couvre une grande partie du graphe. Les instances guaranteed_vc restent avantageuses mais avec un speedup moins prononcé en moyenne.
Exemple extrême : sur un graphe dense où la crown decomposition supprime la quasi-totalité des sommets, la phase de branchement VCB s'applique sur un noyau infime - d'où les speedups à 5 000×.
