Moteur de recherche en ligne pour une bibliothèque numérique de 1 800 livres du projet Gutenberg (plus de 10 000 mots chacun). Trois modes de recherche sont disponibles : mots-clés (indexing par arbre), recherche exacte (Knuth-Morris-Pratt multilignes) et expressions régulières (pipeline NFA → DFA → mDFA). Les résultats sont triés par pertinence via une combinaison du nombre d'occurrences et de la closeness centrality calculée sur la matrice de Jaccard.
Architecture
Architecture client-serveur : backend en Scala avec le framework Play, frontend Vue.js, scripts Python pour le téléchargement des livres et la génération des graphiques. Le backend pré-calcule l'index et la matrice de Jaccard au démarrage ; la recherche n'engage aucun recalcul lourd.
Indexing par arbre - recherche par mots-clés
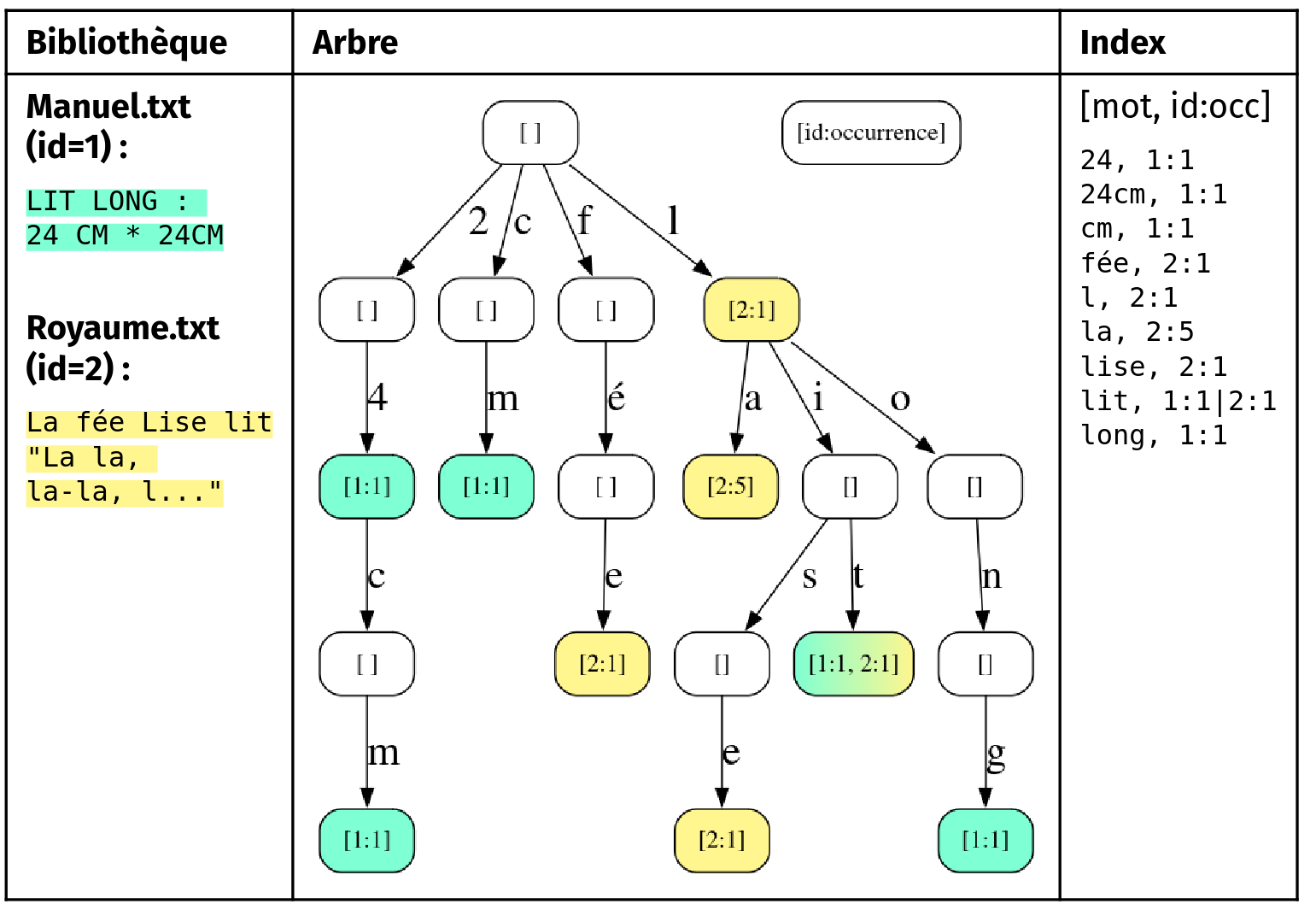
Une approche naïve parcourant tous les mots de tous les livres aurait une complexité O(l × n × r) (livres × mots par livre × mots recherchés), trop lente à chaque requête. Le pré-traitement construit un arbre où chaque chemin depuis la racine encode un mot, et chaque nœud contient la liste des livres contenant ce mot avec son nombre d'occurrences :
case class NodeIndex(
booksToOcc: Map[Int, Int], // Map(book_id → occurrences)
children: Map[Char, NodeIndex]
)Les mots sont normalisés en minuscules (accents, chiffres et lettres non-latines conservés). L'arbre est exporté en map au démarrage - la recherche d'un mot est ensuite en temps constant. Pour une requête multi-mots, le résultat est l'intersection des listes de livres de chaque mot.
Knuth-Morris-Pratt - recherche exacte multilignes
L'algorithme KMP recherche une chaîne exacte en O(n + m) : calcul de la table LPS (carry over) sur le motif en O(m), puis parcours du texte en O(n), sans retour en arrière. Pour permettre la recherche sur plusieurs lignes, les retours à la ligne sont remplacés par des espaces avant l'exécution. La recherche est case-sensitive par choix - elle cible les citations exactes et les noms propres.
Avant de lancer KMP sur tous les livres, un filtre par l'index sélectionne les candidats contenant les mots extraits du motif (ou des mots les contenant), réduisant significativement le volume traité.
Pipeline automate - recherche par expression régulière
La recherche par RegEx suit un pipeline en cinq étapes :
- RegEx Tree - parsing de la RegEx en arbre syntaxique (nœuds : symboles et caractères) dont le parcours infixe redonne la RegEx.
- NFA (Aho-Ullman) - construction du NFA par parcours préfixe de l'arbre, en appliquant les règles de transformation de base récursivement. Complexité
O(m). - DFA (Rabin-Scott) - déterminisation par la méthode des sous-ensembles : tous les états atteignables par une même transition sont regroupés en un seul état. Complexité
O(2ᵐ)dans le pire cas. - mDFA (Brzozowski) - minimisation par double transposition + déterminisation. Le mDFA obtenu est ensuite utilisé pour la reconnaissance.
- Reconnaissance - parcours du texte caractère par caractère en mettant à jour l'état courant. Plusieurs états courants sont maintenus simultanément pour gérer les cas où un début de chaîne matche partiellement (ex. : RegEx
(abc)|(bg), texteabg). Complexité résultante :O(n × m).
Les optimisations apportées au projet egrep de base : correction du comportement de .* par maintien de l'ensemble des états précédents, remplacement des ArrayBuffer de transitions par des Map(lookup en temps constant), réduction du nombre d'objets en mémoire en passant des références Edge à des Char. Même filtre par l'index qu'en KMP appliqué avant la recherche RegEx.
Similarité Jaccard et closeness centrality
La matrice de Jaccard est pré-calculée au démarrage : pour chaque paire de livres (A, B), l'indice J(A, B) = |mots(A) ∩ mots(B)| / |mots(A) ∪ mots(B)| est calculé une seule fois (la symétrie évite de parcourir deux fois la même paire). La matrice alimente deux usages : suggestions de livres similaires à celui consulté, et tri des résultats par pertinence.
Le tri par pertinence combine le nombre d'occurrences du motif (mots-clés et KMP) et la closeness centrality du livre dans le graphe de Jaccard : centrality(v) = (n − 1) / Σ d(u, v). Les livres les plus centraux sont ceux dont le vocabulaire se retrouve le plus dans les autres livres. Exemple extrême : « The New McGuffey Fourth Reader » (manuel éducatif contenant des extraits d'autres œuvres) atteint l'indice maximal de 1,510 ; « Pi to 1 000 000 places » (quasi-exclusivement des chiffres) obtient le minimum à 1,000.
Performances (1 800 livres, machine 4 threads / 8 Go RAM)
| Motif | Mots-clés | KMP | RegEx |
|---|---|---|---|
Dracula | 1 / 488 ms | 1 / 413 ms | 1 / 337 ms |
fireman | 92 / 381 ms | 89 / 1,51 s | 89 / 1,49 s |
the | 1 799 / 289 ms | 1 799 / 9,36 s | 1 799 / 573 ms |
God divided the light from the darkness | 924 / 2,39 s | 2 / 10,34 s | 0 / 8,29 s |
and with the for | 1 793 / 905 ms | 13 / 7,81 s | 8 / 22,52 s |
Les recherches sur un seul mot peu fréquent sont sub-secondes. Les cas lents impliquent des mots très courants forçant les algorithmes à parcourir la quasi- totalité de la bibliothèque. La différence de résultats entre KMP et RegEx pour les requêtes multilignes s'explique par l'absence de support multiligne côté RegEx.


